Dave Thompson November 24, 2025 482 Views
In the world of SEO, crawling is where it all begins. It’s the discovery process where search engine bots, often called spiders or crawlers, travel across the internet to find new and updated content. Think of it as the first handshake; without it, your website is essentially invisible to search engines like Google.
The Secret Life of Search Engine Crawlers
To manage how your website appears in search engine results, it’s crucial to grasp how search engines perform their crawling tasks. Imagine the internet as a massive, continuously expanding library containing over 1.8 billion websites. Search engine crawlers function like diligent librarians, exploring every aisle and shelf. Their initial task is not to read and organize each book—that comes later. At this stage, they aim to identify the book’s existence and record its location.
These automated bots begin with a list of known web pages and follow the links on those pages to find new ones.
They jump from link to link, continuously charting the web and uncovering content. In this process, using Agency Platform can help manage your website’s visibility in search engines effectively.
- Brand new websites
- Changes to existing pages
- Dead or broken links
This discovery mission never stops. Bots from the major search engines are climbing up the web 24/7, with Googlebot alone making billions of requests every single day. This constant exploration ensures their information is as fresh as possible.
From Discovery to Ranking
Crawling is just the first step in a three-part process that ultimately leads to search rankings. This infographic explains how crawling, indexing, and ranking work well together.
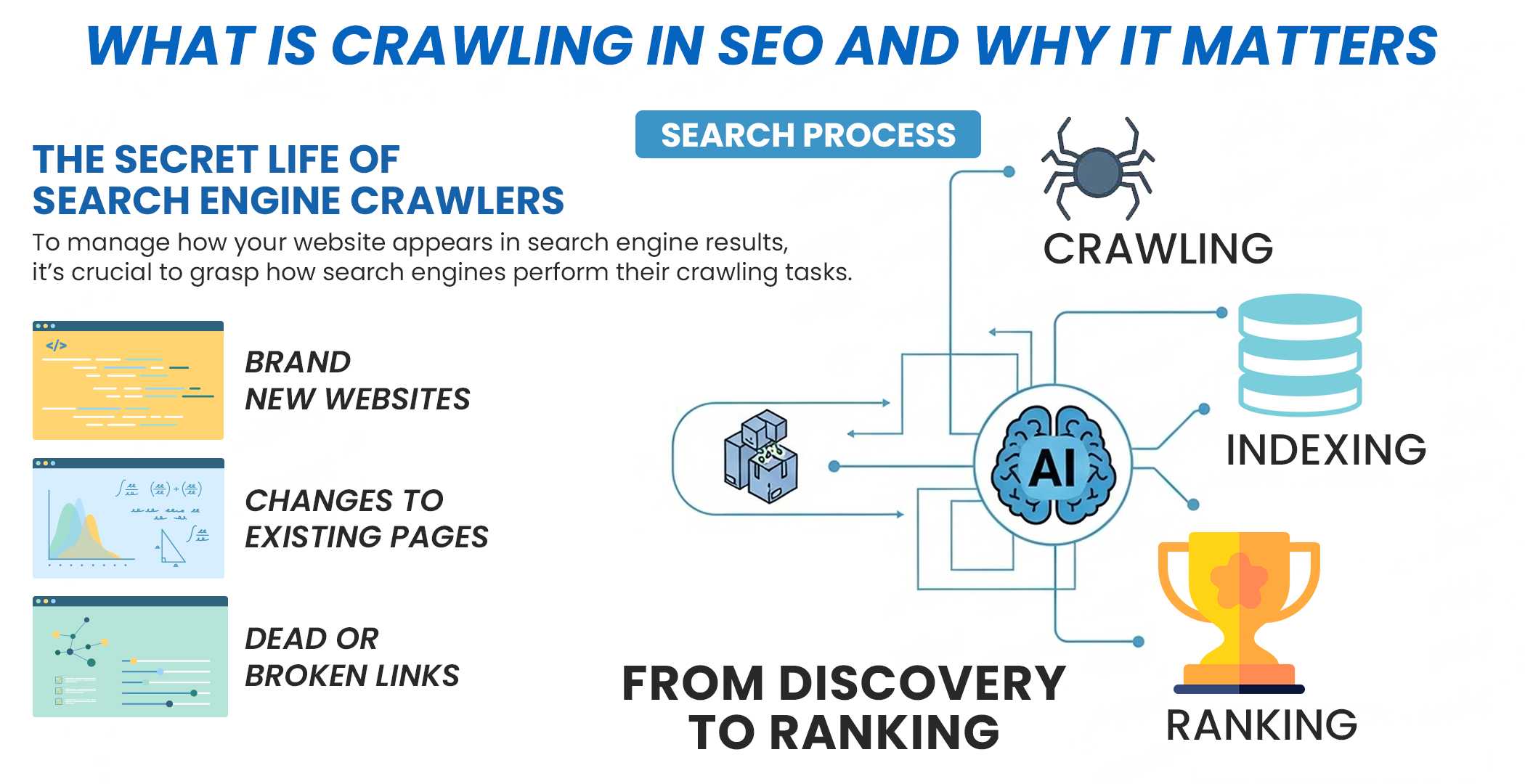
Crawling feeds directly into indexing, where the discovered content is stored and organized.
A page can only be considered for ranking after it has been successfully crawled and indexed.
To make this crystal clear, let’s break down the key differences between these three crucial stages.
Crawling vs Indexing vs Ranking at a Glance
| Stage | What It Is | Simple Analogy |
|---|---|---|
| Crawling | Search engine bots discover your content by following links. | A librarian finds a new book and notes its existence and location in the library. |
| Indexing | Google analyzes and stores the crawled content in a massive database. | The librarian reads the book’s cover, table of contents, and a few pages to categorize it and add it to the library’s catalog. |
| Ranking | When a user searches, Google’s algorithms pull the best results from its index. | A visitor asks the librarian for a book on a specific topic, and the librarian recommends the most relevant and authoritative books from the catalog. |
Each step is completely dependent on the one before it. No crawling means no indexing, and no indexing means no chance of ranking.
Key Takeaway: You can’t rank for keywords if your pages aren’t even crawled. Making sure search engine bots can easily find and access your content is the most fundamental task in all of SEO.
This first step is purely about discovery. The really complex work of figuring out what your page is about and how it stacks up against the competition happens later. You can learn more about the functioning of Google’s search algorithms in our detailed guide. But for now, just know that mastering this initial phase is essential for any successful SEO strategy.
Each step is totally dependent on the one before it. No crawling means no indexing, and no indexing leads to no chance of ranking.
Key Takeaway: You can’t rank for keywords if your pages aren’t even crawled. Making sure search engine bots can easily find and access your content is the most fundamental task in SEO.
This first step is purely about discovery; the complexity of figuring out what your page is about and how it stacks up against the competition begins later. You can learn more about the functioning of Google’s search algorithms in our detailed guide. But for now, know that mastering this initial phase is essential for any successful SEO strategy.
How Bots Navigate Your Website
Search engine crawlers systematically access your website, following a process designed for efficiency. Major bots, such as Googlebot, navigate the web by tracking hyperlinks.
This process begins with a seed list of known web pages from previous crawls, along with sitemaps provided by website owners. Crawlers visit these pages, carefully identifying every link they encounter. New links are added to an expanding queue of pages to be crawled next, creating an ever-growing map of the internet where links serve as roads connecting different locations (your web pages). A strong internal linking structure resembles a well-organized city grid, facilitating easy discovery of all parts of your site by bots.
For optimal performance, services from Agency Platform can assist in ensuring your website’s structure is efficient and accessible, improving its visibility to these crawlers.
The Crawler’s Toolkit
While following links is their bread and butter, crawlers have a few other tools to discover content even more effectively. One of the most critical is the XML sitemap. The easiest way to think of a sitemap is as a direct, hand-drawn map you give to the crawler, pointing out all the important pages you want it to find.
Instead of waiting for a bot to slowly discover a new page through a long chain of links, a sitemap hands it a clean, organized list. This can seriously speed up the discovery process, especially for:
- New Websites: Helps bots find your content for the very first time.
- Large Websites: Ensures pages buried deep within your site architecture don’t get missed.
- Sites with Few External Links: Provide bots a direct path when natural link discovery is going slow.
This diagram from Google perfectly illustrates the basic crawling process. It starts with a set of known URLs and spiders outward by following the links it finds.

As you can see, crawlers build out their massive list of URLs by hopping from one page to the next via links. This discovery work forms the foundation of what will eventually get indexed and ranked.
A Never-Ending Journey
Crawling is an ongoing process. Search bots continuously explore and revisit sites to ensure their information is current and accurate. They return to your site to detect any changes, discover new content, and verify the status of existing links. The frequency of these visits often relates to how regularly you update your content.
Agency Platform services can help improve your site to boost crawling efficiency and make sure updates are quickly reflected in search engine results.
Key Insight: A site that consistently publishes fresh, high-quality content is sending a strong signal to crawlers that it’s a place worth visiting more often. This helps your updates and new pages get found and indexed much faster.
The sheer scale of this operation is challenging. In fact, between mid-2023 and mid-2024, Googlebot crawling traffic shot up by a staggering 96%. This explosion highlights the importance of maintaining a technically sound website that crawlers can navigate without hitting any roadblocks. You can learn more about the rise of bot traffic from Cloudflare.
Mastering Your SEO Control Panel
You might think search engine crawlers are wild, autonomous bots that you have no say over, but you actually have a surprising amount of control. It’s time to move from theory to action. You have a specific set of tools at your disposal to guide these bots, protect sensitive parts of your site, and fix common problems before they can ever hurt your SEO.
Think of it as your website’s command center for crawler management. This isn’t about putting up a “Keep Out” sign for search engines; it’s about providing clear, polite instructions so they can do their job better. By mastering these directives, you can make sure crawlers spend their time on the pages that actually matter to your business.
Giving Directions with Robots.txt
The most fundamental tool in your kit is the robots.txt file. This is a simple text file that lives in your website’s root directory and acts as the official rulebook for any bot that comes visiting. In fact, it’s the very first place a crawler like Googlebot looks before it even thinks about exploring your pages.
You can use it to tell bots which sections of your site they should simply ignore. For example, you’ll definitely want to block them from crawling areas like:
- Admin login pages
- Internal search results
- Shopping cart pages
- Private user profile areas
Important Distinction: A Disallow rule in your robots.txt file only prevents crawling—it doesn’t stop a page from being indexed. If a blocked page gets linked to from somewhere else online, Google can still find it and pop it into the search results. To properly remove a page, you’ll need a different tool.
Page-Specific Instructions with Meta Tags
For more precise, page-by-page control, you’ll turn to meta robots tags. These are little snippets of code you place directly into thesection of a specific webpage’s HTML. They give direct, non-negotiable commands to crawlers about how to handle that one single page.
The most common and powerful directive here is the “noindex” tag. This tag tells search engines, “Feel free to look at this page, but do not, under any circumstances, add it to your index.” It’s the definitive way to keep a page out of the search results, which is perfect for “thank you” pages after a form submission, thin content you’re still working on, or internal campaign landing pages that have no business being public.
Preventing Content Confusion with Canonical Tags
Duplicate content is a classic SEO headache that can seriously confuse search engines and water down your site’s authority. This pops up all the time, often by accident, on e-commerce sites with product variations or blogs that syndicate their content elsewhere.
The fix is the canonical tag. This tag points crawlers to the one true, master version of a page when several similar versions exist. It essentially says, “Hey, I know these pages look alike, but this is the original. Please give all the SEO credit to this one.”
Getting these controls right is a core part of technical SEO. You can find incredibly detailed reports on how Google is crawling and indexing your site within its own tools. For a deeper dive, check out our ultimate guide to using Google’s Search Console for SEO to learn how to diagnose and monitor these elements directly.
Optimizing Your Website Crawl Budget
Search engines have limited resources to allocate to crawling each individual website, leading to the idea of a crawl budget—the time and resources a bot like Googlebot allocates to examining your site.
Imagine it as a shopper on a tight schedule in a large store; they prioritize the most important aisles and avoid wasting time on unproductive paths.
A site’s crawl budget depends on factors like its size, health, and authority. A site that is faster, healthier, and more popular is likely to receive a larger budget, resulting in more frequent visits from search engine bots. While requesting a bigger budget isn’t possible, you can optimize the one you have. Agency Platform services can assist in maximizing your site’s potential, improving its visibility and performance.
This becomes especially critical for large, complex websites with thousands of pages, like e-commerce stores or sprawling blogs. On these sites, wasting crawl budget on low-value pages means your most important content might get crawled less often, delaying its chances to get indexed and rank.
How to Make Every Crawl Count
The key here is making sure bots spend their precious time on your most important content. By strategically guiding them, you make the whole process more efficient, which is a core principle of good technical SEO.
You can preserve your crawl budget by:
- Fixing Broken Links: Every 404 error is a dead end. It’s a complete waste of a crawler’s time.
- Improving Server Speed: Faster server response times mean bots can crawl more pages in less time. It’s that simple.
- Blocking Low-Value Pages: Use your robots.txt file to keep bots away from pages like admin logins, internal search results, or filtered navigation that just creates duplicate content.
- Managing Redirect Chains: Long chains of redirects eat up the budget before a bot even gets to the final destination page.
A well-managed crawl budget ensures that when you publish new content or update a critical page, search engines will discover and process it much, much faster.
This kind of proactive management sends a strong signal to search engines that your site is well-maintained, efficient, and worth their attention.
Google’s Approach to Crawling
It’s important to remember that search engines want to be good partners. Googlebot, for instance, acts as a “good citizen of the web,” setting limits on how fast it crawls to avoid overwhelming your server.
It’s constantly monitoring your server’s health and response times, adjusting its crawl rate so it doesn’t slow things down for your actual human visitors. For a deeper dive, Search Engine Land has a great piece on Google’s crawling behavior.
Ultimately, optimizing your site for speed and efficiency doesn’t just improve the user experience—it directly impacts how effectively search engines can explore and understand your content. For more on this, check out our guide on mastering technical SEO best practices.
Fixing Common Website Crawling Issues
Sooner or later, every website encounters crawling problems, which are an inevitable part of SEO. These issues act as obstacles for search engine bots, consuming your valuable crawl budget and preventing crucial pages from being discovered or indexed. Learning to identify and resolve these problems is an essential skill in technical SEO, and Agency Platform can help streamline this process.
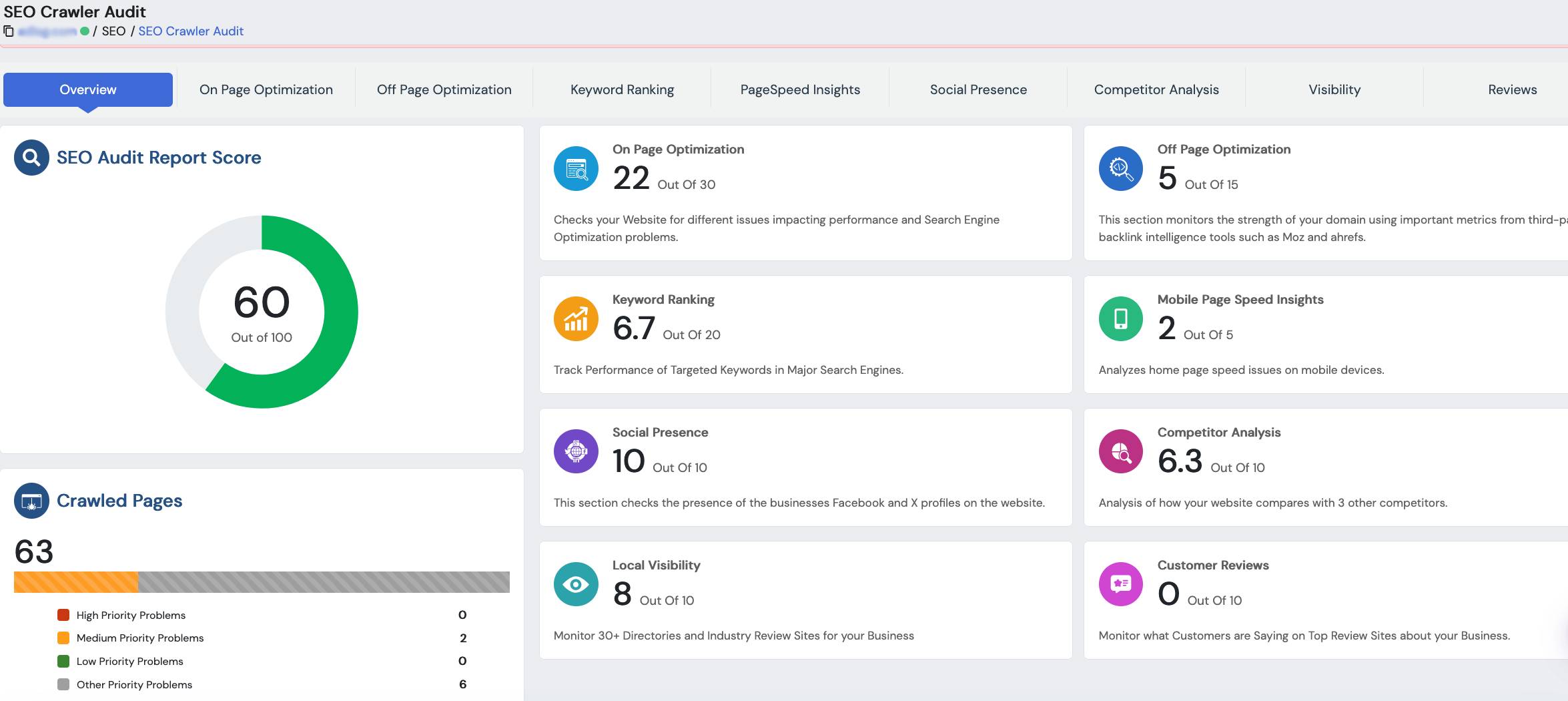
Thankfully, you don’t have to go in blind. Your best friend here is Google Search Console, which acts as your primary diagnostic tool. It gives you detailed reports that show you exactly where Google’s crawlers are hitting a wall. If you get into the habit of checking these reports regularly, you can stop putting out fires and start proactively managing your site’s health.
Diagnosing Problems with Google Search Console
Your first stop inside Search Console should always be the Index Coverage report. This thing is an absolute goldmine of information. It sorts all your site’s URLs into four buckets: Error, Valid with warnings, Valid, and Excluded. For our purposes, the “Error” and “Excluded” sections are where the action is.
This is where you’ll uncover the most common crawling headaches, such as:
- 404 (Not Found) Errors: These are total dead ends. A bot follows a link to a page that isn’t there anymore, and poof—a piece of your crawl budget is gone for nothing.
- Redirect Issues: Long chains of redirects are a classic crawler-killer. If a bot has to jump from Page A to Page B to Page C, it might just give up before reaching the final destination.
- Blocked by robots.txt: This means your own robots.txt file is telling crawlers to stay away from pages they might actually need to see. It’s an easy mistake to make.
- Discovered – currently not indexed: This is Google’s way of saying, “We found this page, but we’re not going to bother crawling it right now.” This often happens when Google thinks the page is low-quality or when your crawl budget is stretched too thin.
Key Insight: A site littered with 404 errors looks neglected to search engines. It’s estimated that roughly 10% of all internal links on an average website are broken, which adds up to a massive drain on your crawl budget. Fixing these is a quick and easy win.
Practical Fixes for Common Issues
Once you’ve found a problem, you’ve got to fix it. Each issue has a specific solution that clears the path for crawlers, ensuring your valuable content finally gets the attention it deserves.
To make things easier, I’ve put together a quick-reference table for tackling these common crawling roadblocks.
Common Crawl Issues and Their Solutions
| Crawl Issue | Why It’s a Problem | How to Fix It |
|---|---|---|
| 404 ‘Not Found’ Errors | Wastes crawl budget and creates a poor user experience. | Update the internal link to point to the correct URL or set up a 301 redirect to a relevant, live page. |
| Redirect Chains | Consumes crawl budget and can slow down page loading times. | Eliminate the intermediate steps. Update all internal links to point directly to the final destination URL. |
| Orphaned Pages | Pages with no internal links are very difficult for crawlers to discover. | Find relevant pages on your site and add internal links pointing to the orphaned content. Add it to your XML sitemap. |
| Accidentally Blocked Pages | Important pages may be blocked from crawling by a rule in your robots.txt file. | Review your robots.txt file and remove or modify the Disallow rule that is blocking the specific page or directory. |
Think of this table as your first-aid kit for crawl issues.
By making a habit of checking for these problems and putting these fixes into practice, you can ensure that search engine bots can move through your website smoothly and efficiently. This proactive approach to what is crawling in SEO not only protects your crawl budget but also helps your content get indexed faster, building a much stronger foundation for your entire SEO strategy.
The New Age of AI and Web Crawling
For years, the world of web crawling was a pretty straightforward affair. You had your usual visitors—mostly search engine bots like Googlebot—and you knew what they were there for. That era is officially over. We’re now dealing with a massive wave of AI crawlers, like OpenAI’s GPTBot and Google’s Gemini, and they aren’t here for search rankings. They’re here to collect staggering amounts of data to train large language models.
These new bots are completely changing the traffic dynamics of the modern web. The rise of AI isn’t just a trend; it’s a tidal wave. In just one year, traffic from OpenAI’s GPTBot exploded with a 305% increase in requests. This incredible surge catapulted it from the 9th to the 3rd most active crawler on the web, signaling a major shift in who—and what—is visiting your site. You can dig into more of this data on Cloudflare’s analysis of bot traffic evolution.
The Strategic Dilemma for Site Owners
This flood of new crawlers introduces a critical question for anyone managing a website: do you block these AI bots to save server resources for traditional search engines, or do you let them in?
Blocking them is simple enough with a quick robots.txt update. But allowing them access could mean your content gets woven into future AI-powered answers and products, potentially opening up entirely new channels for visibility and traffic.
The choice isn’t just a technical one; it’s deeply strategic. How you decide to handle AI crawlers today could directly impact your brand’s visibility in the next generation of search, chatbots, and other information discovery tools.
Successfully navigating this diverse bot ecosystem requires a forward-thinking approach. It’s now more important than ever to monitor your log files, see who’s crawling your site, and understand their purpose. The real goal is to strike a balance between preserving your resources now and future-proofing your content for an AI-driven web.
Frequently Asked Questions About SEO Crawling
We’ve walked through the fundamentals of website crawling, from how bots find their way around your site to putting out common fires. But theory is one thing—let’s tackle some of the practical questions that always come up when you start applying this knowledge.
How Often Does Google Crawl My Website?
There’s no magic number here. The frequency of Googlebot’s visits really depends on the type of site you’re running. A major news publisher pushing out content every hour might get crawled constantly throughout the day. On the flip side, a small, static website for a local business might only see a crawler pop in every few weeks.
A few key factors play into this schedule:
- Site Authority: Big, established sites that are trusted sources tend to get more attention from crawlers.
- Update Frequency: If you’re consistently publishing fresh, high-quality content, search engines learn to check back more often to see what’s new.
- Site Health: A website that loads quickly and has minimal errors is just plain easier for bots to get through, making it a more attractive place for them to visit.
Can I Force Google to Crawl My Website Faster?
You can’t exactly force Google to do anything, but you can definitely give it a strong nudge in the right direction. It’s all about sending clear signals that something new and important is ready to be seen.
Submitting an updated XML sitemap through Google Search Console is always a smart move. If you have a specific, high-priority page you want crawled ASAP, use the “Request Indexing” feature in the URL Inspection tool. This often gets a bot to your page within a day or two.
Does Blocking a Page in Robots.txt Remove It from Google?
This is a huge and surprisingly common mistake. Blocking a page with your robots.txt file only tells Google not to crawl it. It doesn’t remove it from the index. If that page was already indexed or if other websites link to it, it can absolutely still show up in search results—usually with a title but no meta description.
How Agency Platform Improves Your Website’s Crawlability
One of the most effective ways to ensure search engines can crawl your website efficiently is by using a dedicated SEO management system like Agency Platform. Their suite of tools is designed to streamline technical SEO tasks that directly impact how search engines discover your pages. With automated site audits, detailed crawl diagnostics, and real-time monitoring, Agency Platform identifies broken links, redirects, duplicate content, and structural issues that commonly disrupt crawling. It also helps optimize sitemaps, improve internal linking, and ensure that important pages are easily accessible to bots. By resolving hidden crawl barriers and strengthening your overall site architecture, Agency Platform makes it far easier for search engines to navigate your content—ultimately helping your pages get crawled, indexed, and ranked faster.
To properly remove a page from Google’s search results, you have to use the ‘noindex’ meta tag. Placing this tag directly on the page is the only definitive way to tell Google, “Hey, don’t include this in your index.”
At Agency Platform, we live and breathe technical SEO, providing the tools and expertise to make sure your clients’ sites are primed for crawling and indexing. See how our white-label SEO dashboard can streamline your agency’s entire workflow and drive the results your clients expect. Learn more about our all-in-one solution.



